No es la primera vez que sale por aquí el tema de la
estimación software, una de las áreas menos madura en las organizaciones de
desarrollo, como comentábamos hace tiempo revisando datos reales de proyectos software;
“No se puede predecir lo que no se puede medir” (Norman
Fenton)
Comentaba McConnell (en mi opinión quien tiene los
trabajos más prácticos sobre estimación software) que “una estimación
software es una predicción de cuánto tiempo durará o costará un proyecto”.
El propósito de una estimación software es determinar si los objetivos, los
tiempos de que disponemos para realizar el proyecto, son suficientemente
realistas.
Hacer una buena estimación software antes de ofertar un
proyecto nos puede ayudar a detectar proyectos que no conviene abordar y que no
son rentables. Aunque la realidad diga que normalmente negocio, o la parte
comercial, fija inamoviblemente, y sin estimación previa, el tiempo del
proyecto, esto no debería evitar las estimaciones, ya que estas nos ayudarán
entonces a saber de qué tamaño es el problema en que nos hemos metido. Mejor
saber al principio que es imposible hacer el proyecto en el tiempo ofertado que
al final del plazo, cuando ya hay muy poco margen de maniobra.
Existen numerosos métodos de estimación software, si bien
estos se pueden clasificar en dos grandes grupos: aquellos que siguen un
enfoque heurístico o los que siguen un enfoque paramétrico.
Los métodos heurísticos estimación software
Los métodos heurísticos se basan en la experiencia, y los
principales son:
- El método basado en juicio experto. Más comúnmente llamado “a ojo”, y que consiste básicamente en preguntar a alguien con experiencia (o sin ella) cual es en su opinión la estimación software. Y que como podéis deducir… es el método más usado. Pero que tiene el problema de que se depende mucho del experto, de la experiencia que tenga y que además tiene el riesgo de que un día el experto deje la empresa y nos quedemos sin forma de estimar.
- El método por analogía. Que es una importante evolución del anterior, ya que se basa en experiencias documentadas de cómo fueron los tiempos en proyectos previos. El método compara el proyecto a estimar con proyectos terminados previamente que sean similares. Aquí la importante aportación es que disponemos de un método, y de que la experiencia se va guardando en una BBDD (o más comúnmente en una hoja Excel).
Los métodos paramétricos de estimación software
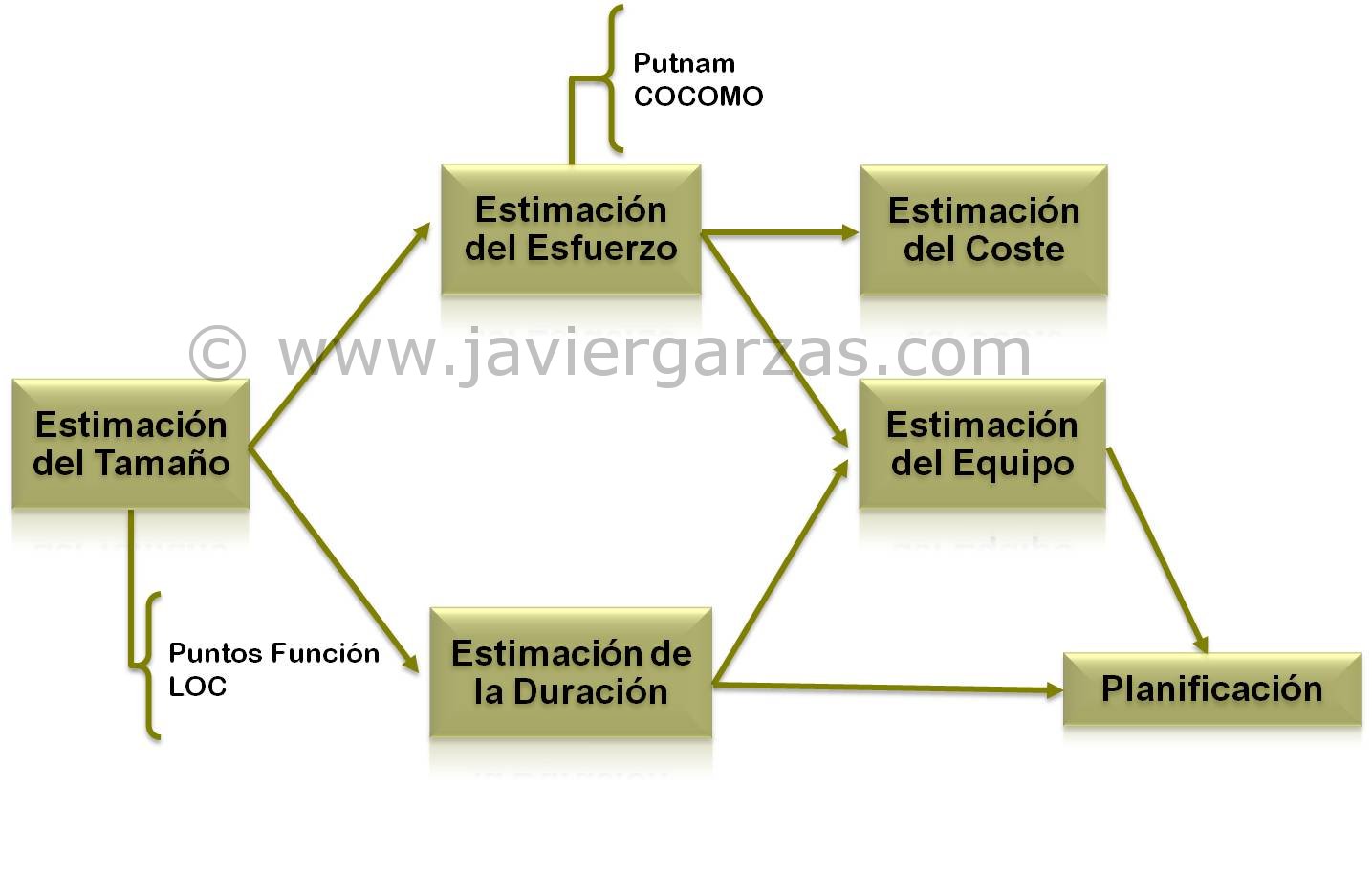
- COCOMO (Constructive Cost Model) II, de Boehmn, que estima el esfuerzo (horas hombre) del proyecto. Para estimar el esfuerzo requiere previamente una estimación del tamaño (funcionalidad, líneas de código, etc., este tema lo veremos luego).
- SLIM (Software LIfecycle Management), de Putnam, que de manera similar contiene un conjunto de fórmulas de estimación software. Estas fórmulas se extrajeron de estudiar grandes bases de datos de proyectos, observando cómo se comportaron la estimación software y distribuciones de esfuerzo.
Los dos anteriores sirven principalmente para obtener una
estimación del esfuerzo (horas hombre de proyecto) y se basan que exista
previamente un cálculo del tamaño del software a desarrollar. Para determinar
el tamaño del software se utilizan principalmente dos unidades de medición: las
líneas de código y los puntos función. Como las líneas de código son poco
exactas, lo normal es estimar el tamaño en puntos función, y para ello existen:
- · Numerosos métodos de estimación software basados en puntos función (FPA de IFPUG, COSMIC-FFP, Puntos Casos de Uso, etc.), que estiman el tamaño funcional de un producto software desde los requisitos.
“Cuando puedes medir y expresarte
con números sabes realmente de lo que hablas; pero cuando no puedes medir,
cuando no puedes expresarte con números, tus conocimientos son escasos y
poco satisfactorios” (Lord Kelvin)
La métrica más obvia para estimar
el tamaño de un producto software es la LOC (Lines Of Code), pero esta métrica
suele tener muchos problemas. Algunos problemas de utilizar LOC como métrica
para estimar el tamaño son: la falta de una definición universal de qué es una
línea de código (¿un conjunto de tokens? ¿lo que hay antes de un punto y coma?,
etc.), su dependencia del lenguaje de desarrollo (no es lo mismo una línea en
Java que en C++), la dificultad de estimar LOC en fases iníciales del
desarrollo, que no está claro que un número de LOC corresponda con un
número de funcionalidades desarrolladas (la misma funcionalidad se puede
desarrollar con muy diferentes números de LOC), etc. Para paliar estos
problemas, surgió una métrica para medir el tamaño en base a los requisitos,
funcionalidad, y no en la tecnología que se va a utilizar, denominada puntos
función (PF).
Los Puntos Función son “una
métrica para establecer el tamaño y complejidad software en base a la cantidad
de funcionalidad requerida y entregada a los usuarios” o “una función que
mide el tamaño lógico o funcional de los proyectos”.
Así como existe el “metro” como
unidad de medición para longitudes, Puntos Función es “el metro” para medir el
tamaño de una aplicación de software. Aunque para ser exactos, los Puntos
Función no serían como el “metro”, ya que no son una medida universal, y
prácticamente no hay dos empresas que midan Puntos Función de la misma manera,
y hay muchos métodos de calcular los Puntos Función. Ejemplos, algunos de los
métodos que más se usan (o más hemos visto nosotros en empresas) para calcular
los Puntos Función.
Comentarios
Publicar un comentario